
Multi Agent Actor-Critic for Mixed Cooperation-Competitve Environments
이 논문을 읽게 된 이유: Homogeneity와 Heterogeneity에 대한 고민. Policy Parameter를 Agent 간에 공유가 이루어질 경우에는 Homogenous한 가정 밖에 할 수 없다. 이것을 어떻게 깰 것인가? NIPS 2017 PDF
Introduction
-
Each agent’s policy is changing as training progresses
-
The environment becomes non-stationary from the perspective of any individual agent
→ learning stability challenges, preventing the straightforward use of past experience replay.
→ Crucial for stabilizing deep Q-learning. Q) Why esp Q-learning? since violating stationary assumption required for convergence of Q-learning. Also the experience replay buffer, helping to stabilize DQN, cannot be used when \(P(s'|s, a, \pi_{1}, \cdots, \pi_{N}) \neq P(s'|s, a, \pi'_{1}, \cdots, \pi'_{N})\) for any \(\pi_{i} \neq \pi'_{i}\)
→ Policy-Gradient. Exhibit very high variance when coordination of multiple agents is required Q) Why? since an agent’s reward usually depends on the actions of many agents, the reward conditioned only on the agent’s own actions (when the actions of other agents are not considered in the agent’s optimization process) exhibits much more variability, thereby increasing the variance of its gradients.
-
Propose the learning algorithm:
1) To learn policies that only use local infomation.
2) Model-free
3) Cooprative and Competitive
-
Adopt the framework of centralized training with decentralized execution
→ Allowing policies to use extra information to ease training , so long as this information is not used at test time. → Q function canot contain differenc information at training and test time. → Thus, Extension of Actor-Critic!
- Critic: augmented with extra information about the policies of other agents (or might be programmed to infer those policies)
- Actor: access to local information only. After training is completed, only the local actors are sued.
Related Work
- Gupta et al, 2017: Policy Parameter sharing.
- Foester et al, 2017: A single centralized critic for all agents (same reward), No communication, Recurrent Policies with feed-forward critics, Discrete policies.
Methods
-
Assumption:
1) the learning policy can only use local information at execution time 2) Model free 3) No communication channel → For the general-purpose multi-agent learning algirhtim
-
Algorithm (MADDPG):
1) \(N\) agents
2) Policy parameters \(\theta=\{ \theta_{1}, \cdots, \theta_{N}\}\)
3) Policy \(\pi=\{\pi_{1}, \cdots, \pi_{N}\}\)
4) Some state information \(x = (o_{1}, \cdots, o_{N})\)
5) Centralized action-value function \(Q^{\pi}_{i}(x, a_{1}, \cdots, a_{N})\) → Learned separately, agents can have arbitrary reward structures, including conflicitng rewards
6) Gradient of expected return for agent \(i\) (\(\mathcal{J}(\theta_{i})=\mathbb{E}[R_{i}]\)) : \(\nabla_{\theta_{i}}\mathcal{J}(\theta_{i}) = \mathbb{E}_{s\sim p^{\mu}, a_{i} \sim \pi_{i}} \big[ \nabla_{\theta_{i}} \log{\pi_{i}(a_{i}|o_{i})} Q^{\pi}_{i}(x, a_{1}, \cdots, a_{N}) \big]\)
7) Deteministic Policies: \(\nabla_{\theta_{i}}\mathcal{J}(\mu_{i}) = \mathbb{E}_{x,a \sim \mathcal{D}} \big[ \nabla_{\theta_{i}} \mu_{i}(a_{i}|o_{i}) \nabla_{a_{i}}Q^{\mu}_{i}(x, a_{1}, \cdots, a_{N})|_{a_{i} = \mu_{i}(o_{i})} \big]\), where the experience replay buffer \(\mathcal{D}\) contains the tuples \((x, x', a_{1}, \cdots, a_{N}, r_{1}, \cdots, r_{N})\) (NOTE: \('\) means a delayed version, say \(\mu'\) means the target policy network and \(x'\) is sampled from the target networks. )
8) Updated as: \(\mathcal{L}(\theta_{i}) = \mathbb{E}_{x,a,r,x'}\big[ \big( Q^{\mu_{i}}(x, a_{1}, \cdots, a_{N})-y \big)^{2} \big]\) \(y = r_{i} + \gamma Q^{\mu'}_{i}(x', a'_{1}, \cdots, a'_{N})|_{a'_{j}=\mu'_{j}(o_j)}\) where \(\mu' = \{ \mu_{\theta'_{1}}, \cdots, \mu_{\theta'_{N}} \}\) is the set of target plicies with delayed parameteres $\theta^{‘}_{i}}$
→ 음미를 해보자면, 일반적인 DDPG에서는 \(\theta, \theta'\)를 알아야 하는데 어차피 이 값들은 나 자신(this.agent)이므로 당연히 알고 있어야 하는 파라미터이다. 그런데 여기서는 다른 Agent의 private한 정보를 참조해야만 업데이트가 가능하다. 왜냐? \(a'\)를 만들어내야 \(y\)를 구할 수 있기 때문! 그렇기 때문에 여기서는 Centralized Learning이라 주장한다. 애당초 Multiagent에서 남들의 정보를 안다는 가정 자체가 말이 안되므로, Learning할 때까지만은 Centralized하게 관리하는 형식으로 가는듯 하다. 재미있는 점은 마치 model-based처럼 외부의 환경을 아는듯 학습을 하지만, 그럼에도 불구하고 학습하는 대상은 완전한 환경(environment)가 아니라 내 시점에서는 환경처럼 보이는 다른 Agent의 속성인 것이다.
→ 따라서 Agent \(i\) 시점에서 어떻게 외부의 환경(그러나 다른 Agent)의 policy를 알 수 있을까?
→ 아직도 개념이 잘 안 잡히는 것은 “Q-러닝 알고리즘이 수렴하기 위해 필요한 마코프 가정을 만족하지 못하게 되어 안정적인 학습이 어렵다는 단점을 갖는다. (중략) 반대로, 에이전트 각각의 로컬 Q-함수를 학습하는 대신에 에이전트들의 모든 로컬 관측 상황과 전역 환경 상태(Global state)를 고려하여 모든 에이전트들의 공동행동(Joint action)이 가져올 누적 보상의 기댓값을 예측하는 한 개의 전역 Q-함수를 학습하는 방식도 가능하다. 하지만, 이러한 완전 집중형(Fully centralized)학습 방식은 에이전트의 수가 증가함에 따라 공동행동 공간이 기하급수적으로 증가하기 때문에 에이전트의 수에 제약이 따른다는 단점을 갖는다.” 출처
-
Inferring Policies of Other Agents:
-
Each agent \(i\) can additionally maintain an approximation \(\hat{\mu}_{\phi^{j}_{i}}\) to the true policy of agent \(j, \mu_j\), where \(\phi\) are the parameters of the approximation.
-
This approximate policy is learned by maximizing the log probability of agent \(j\)’s actions, with an entropy regularizer: \(\mathcal{L}(\phi^{j}_{i}) = -\mathbb{E}_{o_j, a_{j}}[\log{\hat{\mu}^{j}_{i}(a_j | o_j)} + \lambda H(\hat{\mu}^{j}_{i})]\)
→ Thus, \(\hat{y} = r_{i} + \gamma Q^{\mu'}_{i}(x', \hat{\mu'}^{1}_{i}(o_1), \cdots, \mu'_{i}(o_{i}), \cdots, \hat{\mu'}^{N}_{i}(o_{N}))\)
-
-
Policy Ensembles:
- Propose to train a collection of $$K$ different sub-policies.
- For agent \(i\), maximizing the ensemble objective: \(\mathcal{J}_{e}(\mu_i) = \mathbb{E}_{k \sim \text{unif}(1, K), s\sim p^{\mu}, a\sim \mu^{(k)}_{i}}[R_{i}(s,a)]\)
- Since different sub-policies will be executed in different episodes, maintain a replay buffer \(\mathcal{D}^{(k)}_{i}\) for each sub-policy \(\mu^{(k)}_{i}\) for agent \(i\).
- \[\nabla_{\theta^{k}_{i}}\mathcal{J}_{e}(\mu_{i}) = \frac{1}{K}\mathbb{E}_{x,a \sim \mathcal{D^{(k)}_i}} \big[ \nabla_{\theta^{(k)}_{i}} \mu^{(k)}_{i}(a_{i}|o_{i}) \nabla_{a_{i}}Q^{\mu}_{i}(x, a_{1}, \cdots, a_{N})|_{a_{i} = \mu^{(k)}_{i}(o_{i})} \big]\]
Expreiments
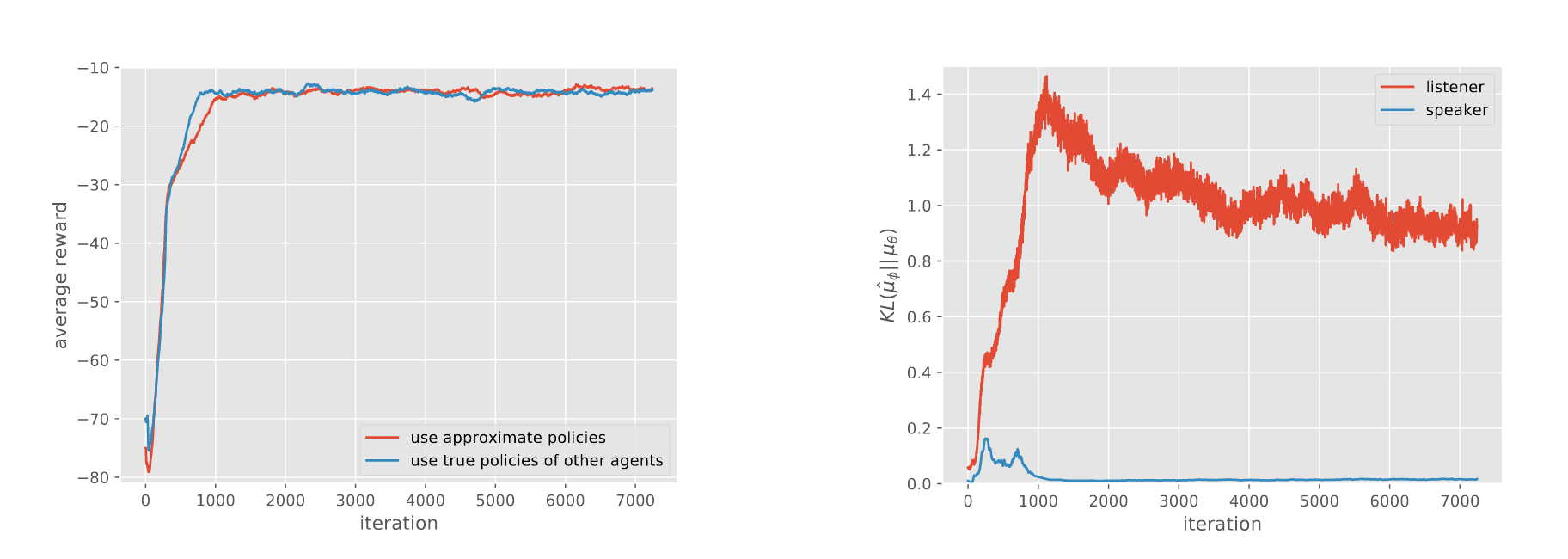
- Approximating other agents’ policies works very well
- Even KL divergenc is very high. **Why?**
??
- Policy가 각기 다르다면 Heterogenous하다고 할 수 있지 않을까?! 그렇다면 이 논문을 통해서 Heterogenous한 agent 사이에서 communication없이도 학습이 가능함을 알 수 있다.
- 각기 다른 policy parameters를 가지고 있기 때문에 학습이 느려지고 lazy 에이전트가 발생할 가능성이 다분하다. 근데 왜 이 논문은 이러한 설정을 했을까? 음. 아마도 Critic에 대응하는 Actor의 경우가 각각의 agent로 대체되기 때문이다. Centralized 되어있는 Critic 일지라도 Actor 하나하나는 각기 다른 Agent이기 때문에 마치 해당 Agent의 Action만을 optimize하는 것처럼 보이나, 결국 전체의 의중을 반영하는 Critic이 매번 update되기 때문에 특히나 해당 Agent i에 대한 파라미터가 업데이트 되므로!
- Credit Assignment 관점에서 바라본다면, 뭔가 lazy할 수 없는 상황이다. 왜냐하면 선생님이 한 명 한 명 다 지켜보고 있는 상황이기 때문
- 그치만 뭔가 석연치 않은 구석이 존재한다. 조금 더 고민을 해볼 필요가 있는 논문인 것 같다…
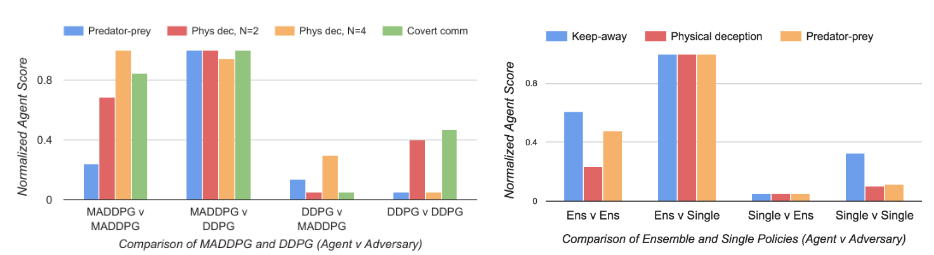
- 물론, Learning에서 centralization이 가능하다는 상황이 전제되지만. 그리고 앙상블 vs Single 실험이 있었는데, 이런 식으로 학습된 두 모델을 비교하는게 재미있을 것 같다.
- 하지만, 저자는 \(N\)에 linear하게 compuation이 증가할 것이라고 하는데, 정말 그러한가? 필요한 파라미터만 해도 2배 정도 더 필요하고, 데이터는 \(\times N\)인데. 일단 전체적으로 모델의 사이즈와 모델을 학습하기 위한 컴퓨팅 파워가 엄청 늘어나버리는 느낌이다.
Leave a comment