
Papers Review
An Analysis of Stochastic Game Theory for Multiagent RL (M.Bowling et al. 2000)
- There is not likely to be an optimal solution to a stochastic game that is indep. of the other agents.
- The algorithms differ on what assumptions they make about the SG and the learning process.
- The main differences are whether a model for the game is available and the nature of the learning process.
- Most GT algorithms require a model of the environment, since they make use of the transition, T, and reward \(R_i\), functions.
- The goal of these algorithms is to compute the quilibrium value for the game rather than finding equilibrium policies.
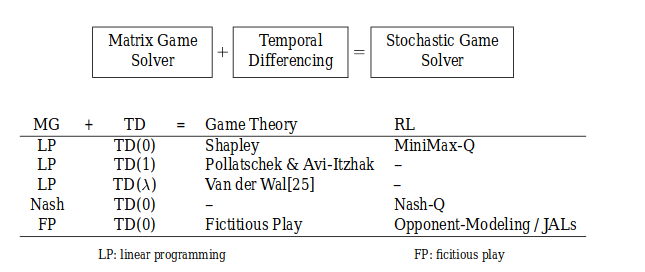
- “Value” operator refers to algirhtms for solving matrix game, either LP or QP.
- RL assume the world is not known, and ony observations of the T and R functions are available as the agents act in the environment.
- Most GT algorithms require a model of the environment, since they make use of the transition, T, and reward \(R_i\), functions.
- The main differences are whether a model for the game is available and the nature of the learning process.
-
Solutions from Game Theory: These algorithms learn a value function over states, \(V(s)\). The goal is for \(V\) to converge to the optimal value function \(V*\).
- Shapley: Zero-sum SGs. Uses a TD learning to backup values fo next states into a simple matrix game, \(G_{s}(V)\). Nearly identical to value iteration for MDPs, with the “max” operator replaced by the “Value” operator.
- Pollatschek & Avi-Itzhak: Introduced an extension of policy iteration. Each player selects the quilibrium policy according to the current value function, makeing use fo the same TD matrix \(G_{S}(V)\).
- cons: Only guaranteed to converge if the transition function T and discount factor \(\gamma\) satisfies a certain property.
-
Solutions from RL: The agents are required to act in the environment in order to gain observations of \(T\) and \(R\). These algorithms focus on the behavior of a singe agent, and seek to find the quilibrium policy for that agent.
- Minimax-Q: Extended the traditional Q-learning algorithms for MDPs to zero-sum SG. It replaces the “max”operator with the “Value” operator. This is the off-policy RL equivalent of Shapley’s “value iteration” algorithm.
- cons: converge to the SG’s equilibrium solution, assuming the other agent executes all of its actions infinitely often.
- Nash-Q: Extended the Minimax-Q to general-sum algirhtm. Requires that each agent maintain Q values for all the other agents. LP solution is replaced with the QP solution.
- cons: the game must have a unique equilibrium.
- Minimax-Q: Extended the traditional Q-learning algorithms for MDPs to zero-sum SG. It replaces the “max”operator with the “Value” operator. This is the off-policy RL equivalent of Shapley’s “value iteration” algorithm.
-
Others
- Fictitous Play
- assumes opponents play stationary strategies.
- maintains information about the average value of each action
- then deterministically selects the action that has done the best in the past.
- nearly identical to single agent value iteration with a uniform weighting of past experience
- Opponent Modeling/Joint action learners(JAL)
- similar behavior to fictitous play.
- Fictitous Play
Multiagent RL for multi-robot systems: A Survey (E Yang et al. 2004)
Frameworks
-
SG-Based
pros)
cons) Always require to converge to desirable equilibria, which means sufficient exploration of strategy space is needed before convergence can be established. Agents have to find and even identify the equilibria before the policy is used at the current state.
-
Algorithms
-
Minimax-Q-learning
-
Nash-Q-learning
-
Friend-or-Foe Q-learning
-
rQ-learning
-
-
-
Fictitous Play
pros) Capable of finding equilibrium in both zeor-sum and general-sum games
cons) adopts deterministic policies and cannot play stochastic strategies
-
Algorithms
- JAL
-
-
Bayesian
pros) Agent can use priors to reason about how its action will influence the behaviors of other games.
cons) Some prior density over possible dynamics and reward distirbution ahve to be known by a learning agent in advance.
-
Policy Iteration
pros) Can provide a direct way to find the optimal strategy in the policy space.
- Algorithms
- WoLF-PHC: complete proof for the convergence properties has not been provied. non-markovian environment are not taken into account at all.
- Algorithms
A comprehensive survey of multi-agent reinforcement learning (L.Busoniu et al. 2008)
-
Challenges in MARL
- The exponential growth of the discrete state-action space in the number of state and action variables
- the curse of dimensionality
-
Specifying a good MARL goal in the general stochastic game
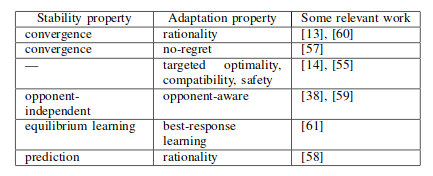
- stability: convergence to a stationary policy
- adaptation: performance is maintained/improved as the other agents are changing their policies
-
Nonstationarity of the multi-agent learning problem
- each agent is faced with a moving-taget learning problem
-
Exploration-Exploitation trade-off
- need to obtain information not only about the environment but also about the other agents
- too much exploration can destabilize the learning dynamics
- The exponential growth of the discrete state-action space in the number of state and action variables
-
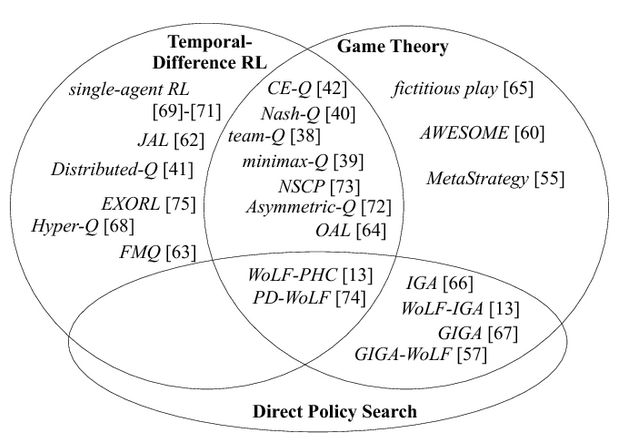
Texanomy
-
Task Types
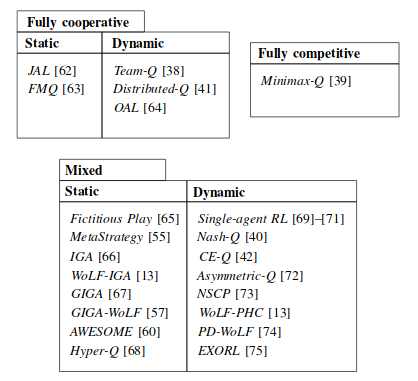
- Mixed Task
- Single-agent RL
- Agent-independent methods
- Nash-Q learning
- Correlated Equilibrium Q learning (CE-Q)
- Agent-tracking methods: Convergence to stationary strategies is not a requirement.
- Static: fictitious play, MetaStrategy, Hyper-Q
- Dynamic: Non-Stationary Converging Policies(NSCP),
- Agent-aware methods: target convergence, as well as adaptation to the other agents.
- Static: AWESOME, IGA/WoLF-IGA/GIGA/GIGA-WoLF,
- Dynamic: WoLF-PHC, EXORL
–> many algorithms for mixed SGs suffer from the curse of dimensionality, and are sensitive to imperfect observations; the latter holds especially for agent-independent methods.
-
Field of origin
-
Deep RL for MAS: A Review of Challenges, Solutions and Applications (T.Nguyen et al, 2019)
- Challenges
- Non-stationarity
- Partial observability
- MAS training schemes
- Continous action spaces
- Transfer Learning

Leave a comment