
Constrative Representation Distillation
Knowledge Distillation에서 Contrastive learning을 활용한 CKD 모델
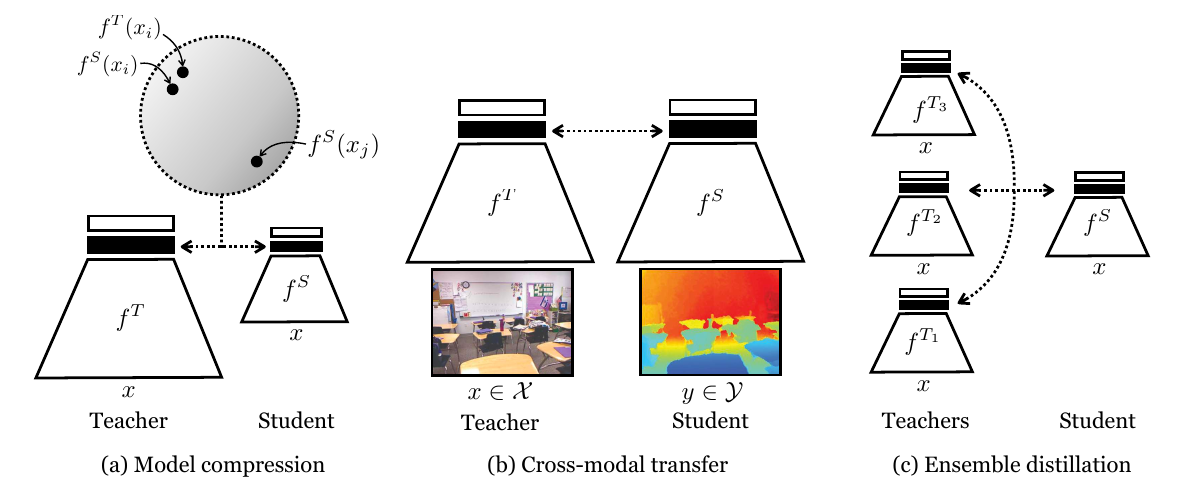
요약
- 아이디어의 중심은 “같은 종류의 pair는 가깝게, 다른 종류의 pair는 멀리” 위치하는 representation structure를 학습한다는 점이다.
- 문제: hinton의 논문은 dimension을 factorized했기 때문에 space 내에서 correlation을 고려하지 않았다는 문제를 가진다.
- 해결: Mutual Information을 도입하여 correlation은 고려하되, 불확실성을 감소시키는 방향(비슷한 것은 가까이, 다른 것은 멀리)으로 학습을 하도록 유도하였다.
- 특히, MI는 p(x,y)와 p(x)p(y)를 어떠한 latent variable을 사용해서 적절하게 lower bound를 설정해서 유도해내었다는 점이서 나중에 써먹을만한 기법이지 않나 싶었음. 뿐만 아니라 distribution q를 discriminator로 분포를 구해내어서 풀어나간게 어떻게 이렇게 생각했나 싶음.
- RKD나 CKD나 기존의 KL divergence가 아니라 뭔가 다른 information을 쓰려고 했던 점이 눈에 띈다. 여기서도 Teacher와 Student의 Mutual Information을 높여준다는 것 즉, Student가 Teacher의 불확실성을 감소시키는 방향으로 넓혀가도록 explicit하게 설정을 해주었다.
생각
- 일단, 모델 보고 있자면, 이렇게 많이 때려박아서 쓰는건 좀 흥미가 떨어진다. 파라미터를 많이 써서 성능을 올리는건 아름답지가 않다고나 할까. 라고 생각하였으나, ensemble은 크게 비중이 없었음.
- Constrative Learning 관련 읽어볼 자료: Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
Leave a comment