
Local Sensitive Hashing
논문1 읽다가 LSH를 공부하면서 미리 정리를 해두지 않으면 또 잊어버릴 것 같아서 정리를 해둠. 해쉬는.. 데이터 구조 수업을 엄청 날로 먹은 탓에 매번 공부해야지 하고 있었는데 이 참에 같이 공부를 해둔다…ㅠ,.ㅠ
Hash Table
- 아주아주 간단한 해쉬테이블에 대한 설명은 다음과 같다.
- Dictionary처럼 우리의 자료 구조는 key와 value를 가지게 된다.
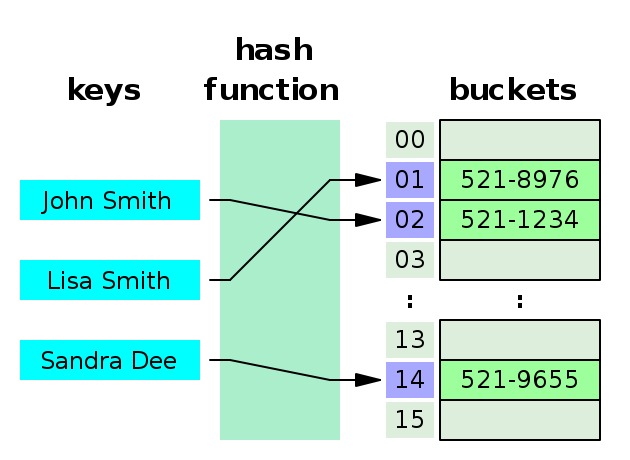
- key는 우리가 알고 있는 데이터, value는 우리가 알고자 하는 데이터이다. 아래 그림에서 이름은 key, 전화번호는 value이다.
- 이 때, hash function을 이용해서 하나의 key 값에 하나의 hash를 부여해준다.
- 예를 들면, ‘Lisa Smith’는 01이라는 해쉬(or hash code)를 지니게 된다.
- (hash, value) 형태로 Bucket에 저장이 된다.
- hash function에 의해 O(1)으로 저장, 삭제, 탐색이 이루어진다.
- 다만, Collision 때문에 항상 O(1)으로 계산이 마무리 되는 것은 아니다.
- Collision으로 생기는 문제를 해결하기 위해서는 chaining 등이 있는데, 이 때 O(1)이라는 계산의 효율성이 저하된다.
LSH
- 기본적인 개념
- 비슷한 key는 비슷한 hash를 가지도록 한다.
-
$$ p-q < r \rightarrow P(h(p) == h(q)) \geq p_1 $$: 가까이 있으면 같은 해쉬 코드를 가질 확률이 높고 -
$$ p-q > cr \rightarrow P(h(p) == h(q)) \leq p_2 $$: 멀리 있으면 같은 해쉬 코드를 가질 확률이 낮음
-
- 이러한 성질은 비슷한 data는 같은 bucket에 들어가게 된다.
- LSH는 collision을 minimize하는데 초점을 두지 않고, 아이러니하게도 maximize하는게 중요하다. 이러한 특징 때문에 데이터 Clustering에도 많이 사용된다.[^2]
- 비슷한 key는 비슷한 hash를 가지도록 한다.
-
방법
-
내게 있어 LSH는 마치 Ensemble-like Dimension Reduction과 유사하게 느껴진다.
-
Hash funtion \(h\)을 이용해서 각각의 key에 해당하는 hash code를 가지게 만든다.
-
그런데, \(h\)가 여러개를 두고 있기 때문에 하나의 key는 \(k\)개의 hash code를 가진다.
-
이는 마치 \(D\) 차원의 데이터를 \(k\)차원의 데이터로 줄여버리는 것과 유사하게 느껴진다.
-
여기서 만들어지는 \(k\)개의 hash code는 vector 형식으로 보여진다.
(이 벡터들의 거리가 원래 데이터의 거리와 유사하게 만드는 것은 뭔가 당연하게 느껴진다)
-
-
Leave a comment