
Federated Learning and Non-iid
FL에서는 non-iid 문제를 어떻게 해결하도록 시도할까에 대한 논문들 정리용. 아아아 어렵다 어려워
Federated Learning with Non-IID Data[^1]
요약
FedAvg는 극단적인 Non-iid 세팅에서 그렇게 robust 하지 않음을 보인다. FedAvg 논문[^3]에서는 Class가 2개까지만 하는 세팅을 사용했었다. 그런데 이 논문에서는 Class를 1개를 가정하고 실험을 진행하면 FedAvg가 영 좋지 않은 성능을 보인다고 주장한다. 논문에서는 FedAvg가 점차 Central model에서 벌어질 수 밖에 없는 이유를 Upper Bound를 두고 풀이를 한다.

- UB는 이전 스텝과 Client와 전체 data distribution의 차이로 구성이 된다.
- 이전 스텝의 영향은 initial w가 달라지면 그게 amplify 된다. (이건 정확하게 이해가 안됨) 여튼, FedAvg는 이걸 기본 가정으로 깔고 가니깐 문제가 없다.
-
$$ p^k - p $$은 Earth Moving Distance로 측정이 가능하다.
그래서 이 UB는 EMD랑 correlation이 있기 때문에 아래와 같은 결과를 가지게 된다. 그리고 이것에 대한 해결책으로 어느정도 i.i.d인 sharing data를 사용하자는 주장을 펼친다.
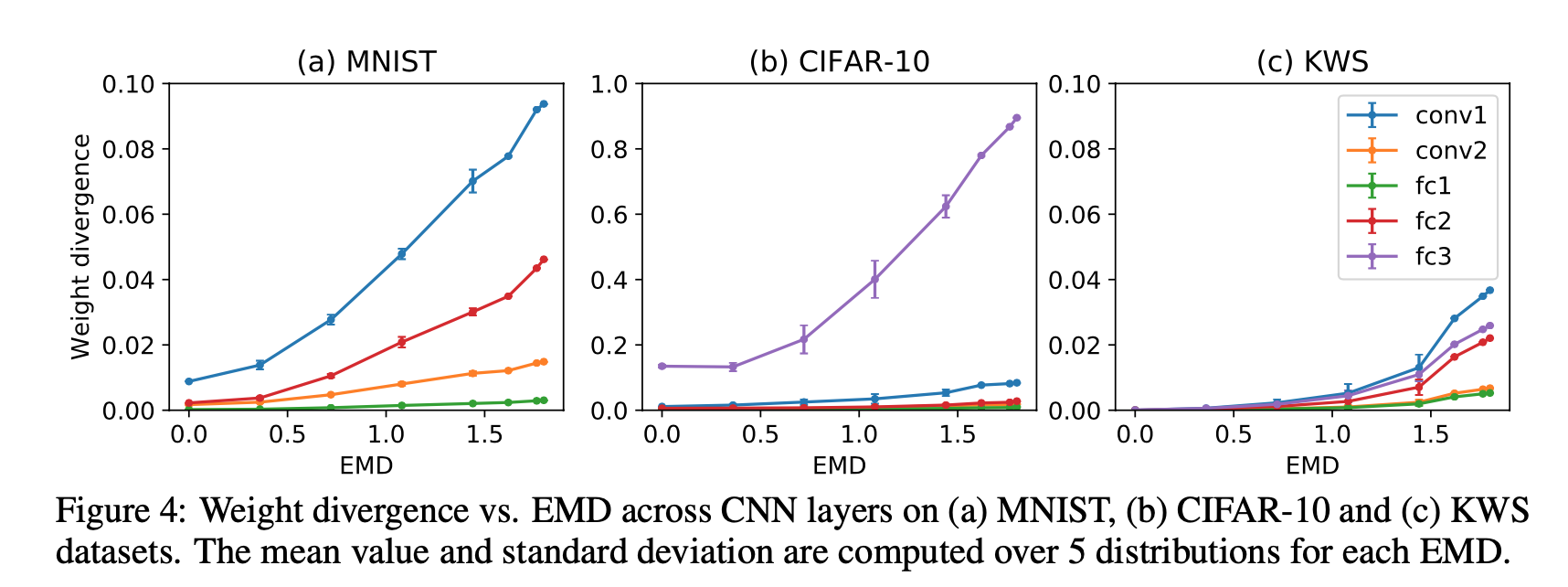
생각
물론 방법론이 그다지 매력적이지는 못하지만 (왜냐하면 FL이 애시당초 Data sharing을 안 하다고 하거니와, 점차 많은 데이터가 쌓여가는 local에서 이러한 설정은 시간이 지남에 따라 희석될 수 밖에 없지 않을까 싶다), 어느 정도 Theoretical한 분석이 있다는 점에서 참고해봄직하다.
가장 큰 문제는 내가 EMD를 계산할 수 없다는 점이다. 전체 distribution을 알아야 얼마나 다를지를 가늠할 수 있을텐데 이걸 어떤 수로 알아낼 수가 있을까??? 그리고 이걸 안다고 할지라도 어떻게 해결할지는 모르겠다. 저자들도 아마 여기서 어찌해결을 못하고 EMD를 줄이는 방향으로 data sharing을 주장했지 싶다.
THE NON-IID DATA QUAGMIRE OF DECENTRALIZED MACHINE LEARNING1
요약
기존 FedAvg 같은 논문들은 커뮤니케이션을 줄이는데만 집중했기 때문에, iid 가정이라든지 non-iid 조건을 약하게 걸어서 결과를 도출했다. 실험적으로 알아낸 사실은 (2번 빼곤 당연한 이야기이긴 한데)
- non-iid 세팅에서 FedAvg, Gaia, Deep Gradient Compression, BSP는 모델에 따라서(AlexNet, GN-LeNet) 성능이 안 좋아지는 결과를 내는데, 이는 non-iid가 기존의 방법에서는 accuracy를 감소시킬 수 밖에 없음을 나타냄.
- Batch Normalization은 non-iid 세팅에 굉장히 민감하고, 이에 반해 Group Normalization은 괜찮은 성능을 보여준다 (그렇다고 해결책이란 말은 아님).
- iid에서 많이 벗어날수록 테스크는 더 어려워진다.
- 근본적인 아이디어는 iid에 많이 벗어나는 partition을 찾아내서 거기서 계속 학습하면서 general model을 업데이트 시키고, 커뮤니케이션에서 accuracy loss가 도달해서 커지는 부분들에서 model이 이동(한다고 설명을 하기는 하지만 그냥 그쪽의 local model에 가중치를 1로 둔다고 생각하면 되는건가..?)
Leave a comment