
Relational Knowledge Distillation
Knowledge Distillation에서 soft targeting을 함과 동시에 좀 더 다양한 장치를 사용할 여지는 없을까?
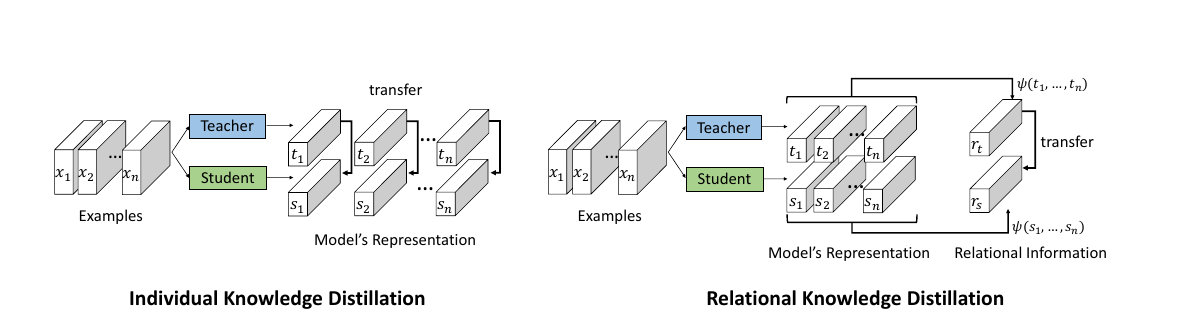
요약
- 마치 또 다른 loss를 써서 학습을 하는 것처럼, 혹은 Regularizer를 집어넣어서 (사실 똑같은 이야기지만) 학습을 하는 것처럼 이 논문도 Pair의 distance와 angle이라는 추가적인 information을 explicit하게 심어준 것이라 볼 수 있겠다.
- Tf-KD에서 어떤 Regularizer를 쓰는게 좋은가라는 질문을 던진게 있는데, 이 논문은 어쩌면 그것과 관련된 논문인 것 같다. 거기서는 일정한 분포를 가지고 Label Smoothing의 uniform 대신에 이걸 사용해보자! 라고 주장했다면 이 논문은, 거기에다가 이런 정보를 포함하게 되면 더 잘 학습이 된다! 라고 주장을 한다.
- 근데 생각해보면 soft targeting에서 추가를 하는 것이 아니라, 일반적인 hard targeting에서 다른 information을 모델링하였다.
생각
- 당연히, relation을 주면 학습이 잘 되는건 분명할텐데 과연 항상 좋은 방향으로만 relation이 작동을 할까? Relation이 제대로 작동이 안 되는 경우는 발생할 수 있을까? 서로 상쇄되는 경우가 발생할까? Regularizer 내부의 것을 조절할 수 있는 장치가 필요할 것이다.
- 뭐랄까, probabilistic하게 풀어낼 수도 있지 싶은데. 아니면 KL을 좀 더 다양하게 해석하여 추가적인 loss term을 만들어낼 여지가 있을 것 같긴하다.
Leave a comment